
Accelerate your data science career with Fractal’s certification! Gain job-ready AI, analytics, and machine learning skills to land top roles. Start today!
Data Integration Made Easy: Exploring the Top 17 ETL Tools and Their Key Features
This blog post covers the top 16 ETL tools for organizations, like Talend Open Studio, Oracle Data Integrate, and Hadoop.
Data integration tools play a critical role in the field of data science by enabling seamless aggregation, transformation, and merging of diverse data sources into a unified and coherent format.
These tools are designed to handle complex data pipelines and facilitate the smooth flow of information from various databases, applications, and platforms, eliminating data silos and ensuring data consistency.
Data scientists heavily rely on these tools to access and harmonize data from disparate sources, allowing them to focus on the core tasks of analysis, modeling, and extracting valuable insights.
With their ability to handle large volumes of data and automate repetitive tasks, data integration tools streamline the data preparation process and enhance the efficiency and accuracy of data-driven decision-making in the realm of data science.
Many organizations today want to use data to guide their decisions but need help managing their growing data sources.
More importantly, when they can’t transform their raw data into usable formats, they may have poor data availability, which can hinder the development of a data culture.
ETL (Extract, Transform, Load) tools are an important part of solving these problems.
There are many different ETL tools to choose from, which gives companies the power to select the best option.
However, reviewing all the available options can be time-consuming.
In this post, we’ve compiled a top 16 ETL tools list, detailing some of the best options on the market.
What is ETL?
ETL is a common approach to integrating data and organizing data stacks. A typical ETL process comprises the following stages:
- Extracting data from sources
- Transforming data into data models
- Loading data into data warehouses
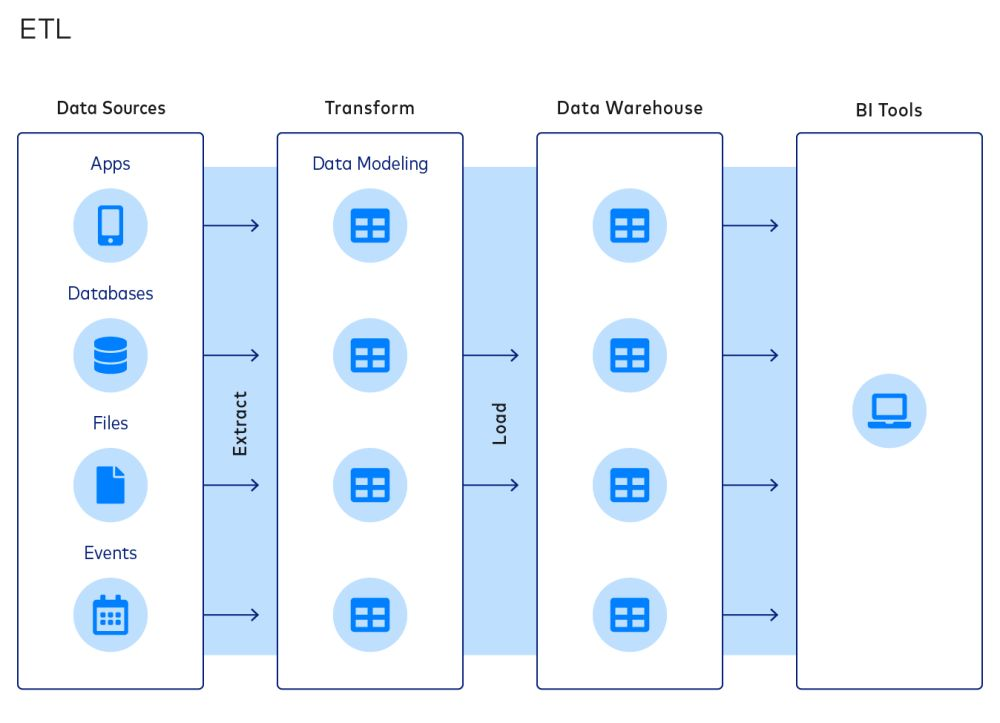
The ETL paradigm is popular because it allows companies to reduce the size of their data warehouses, which can save on computation, storage, and bandwidth costs.
However, these cost savings are becoming less important as these constraints disappear. As a result, ELT (Extract, Load, Transform) is becoming more popular.
In the ELT process, data is loaded to a destination after extraction, and transformation is the final step in the process. Despite this, many companies still rely on ETL.
What are ETL Tools?
Just as the name suggests, ETL tools are a set of software tools that are used to extract, transform, and load data from one or more sources into a target system or database.
ETL tools are designed to automate and simplify the process of extracting data from various sources, transforming it into a consistent and clean format, and loading it into the target system in a timely and efficient manner.
In the next section, we’ll see key considerations data teams should apply when considering an ETL tool.
Key considerations of ETL Tools
Here are three key considerations for a company’s ETL tools.
- The extent of data integration. ETL tools can connect to a variety of data sources and destinations. Data teams should opt for ETL tools that offer a wide range of integrations. For example, teams who want to move data from Google Sheets to Amazon Redshift should select ETL tools that support such connectors.
- Level of customizability. Companies should choose their ETL tools based on their requirements for customizability and technical expertise of its IT team. A start-up might find built-in connectors and transformations in most ETL tools sufficient; a large enterprise with bespoke data collection will probably need the flexibility to craft bespoke transformations with the help of a strong team of engineers.
- Cost structure. When choosing an ETL tool, organizations should consider not only the cost of the tool itself but also the costs of the infrastructure and human resources needed to maintain the solution over the long term. In some cases, an ETL tool with a higher upfront cost but lower downtime and maintenance requirements may be more cost-effective in the long run. Conversely, there are free, open-source ETL tools that can have high maintenance costs.
Some other considerations include:
- The level of automation provided
- The level of security and compliance
- The performance and reliability of the tool.
The Top 17 ETL Tools Data Teams Can Consider
With those considerations in mind, we present the top 16 ETL tools available in the market. Note that the tools are not ordered by quality, as different tools have different strengths and weaknesses.
1. Informatica PowerCenter
Informatica PowerCenter is one of the best ETL tools on the market.
It has a wide range of connectors for cloud data warehouses and lakes, including AWS, Azure, Google Cloud, and SalesForce. Its low- and no-code tools are designed to save time and simplify workflows.
Informatica PowerCenter includes several services that allow users to design, deploy, and monitor data pipelines.
For example, the Repository Manager helps with user management, the Designer allows users to specify the flow of data from source to target, and the Workflow Manager defines the sequence of tasks.
2. Apache Airflow
Apache Airflow is an open-source platform to programmatically author, schedule, and monitor workflows.
The platform features a web-based user interface and a command-line interface for managing and triggering workflows.
Workflows are defined using directed acyclic graphs (DAGs), which allow for clear visualization and management of tasks and dependencies.
Airflow also integrates with other tools commonly used in data engineering and data science, such as Apache Spark and Pandas.
Companies using Airflow can benefit from its ability to scale and manage complex workflows, as well as its active open-source community and extensive documentation.
You can learn about Airflow in the following DataCamp course.
3. IBM Infosphere Datastage
Infosphere Datastage is an ETL tool offered by IBM as part of its Infosphere Information Server ecosystem.
With its graphical framework, users can design data pipelines that extract data from multiple sources, perform complex transformations, and deliver the data to target applications.
IBM Infosphere is known for its speed, thanks to features like load balancing and parallelization.
It also supports metadata, automated failure detection, and a wide range of data services, from data warehousing to AI applications.
Like other enterprise ETL tools, Infosphere Datastage offers a range of connectors for integrating different data sources.
It also integrates seamlessly with other components of the IBM Infosphere Information Server, allowing users to develop, test, deploy, and monitor ETL jobs.
4. Oracle Data Integrator
Oracle Data Integrator is an ETL tool that helps users build, deploy, and manage complex data warehouses.
It comes with out-of-the-box connectors for many databases, including Hadoop, EREPs, CRMs, XML, JSON, LDAP, JDBC, and ODBC.
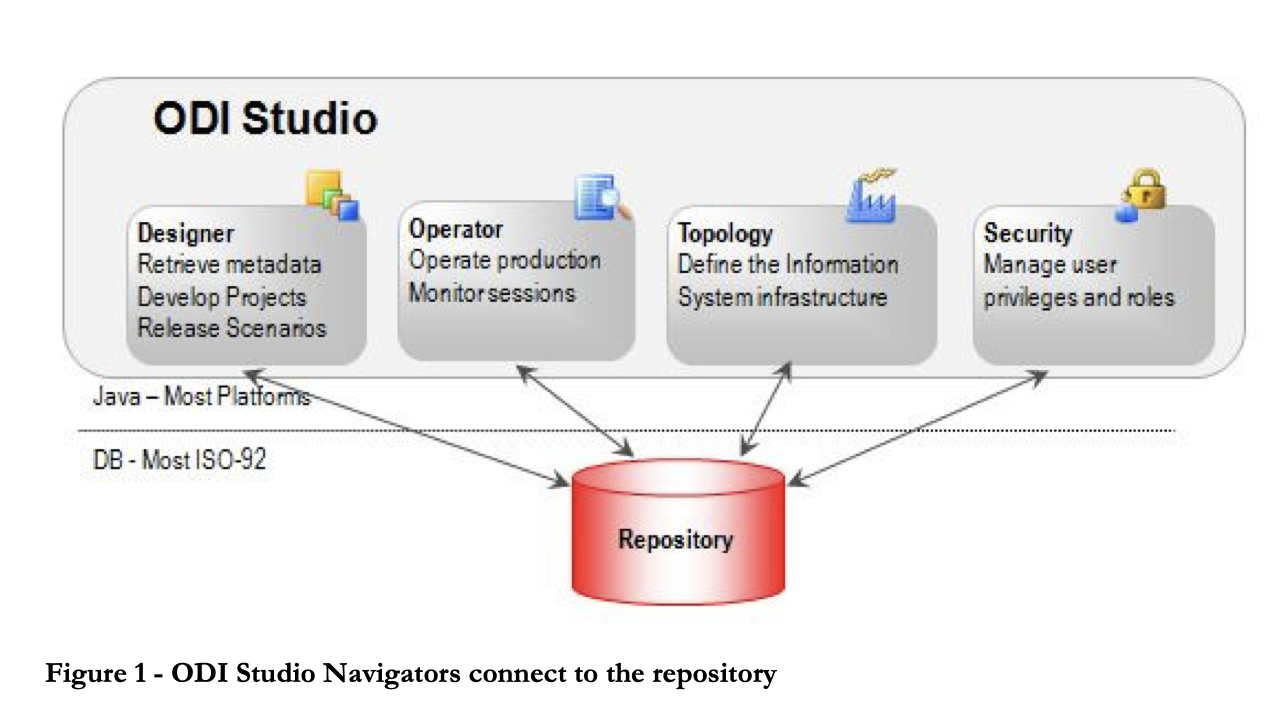
ODI includes Data Integrator Studio, which provides business users and developers with access to multiple artifacts through a graphical user interface.
These artifacts offer all the elements of data integration, from data movement to synchronization, quality, and management.
5. Microsoft SQL Server Integration Services (SSIS)
SSIS is an enterprise-level platform for data integration and transformation.
It comes with connectors for extracting data from sources like XML files, flat files, and relational databases.
Practitioners can use SSIS designer’s graphical user interface to construct data flows and transformations.
The platform includes a library of built-in transformations that minimize the amount of code required for development.
SSIS also offers comprehensive documentation for building custom workflows.
However, the platform’s steep learning curve and complexity may discourage beginners from quickly creating ETL pipelines.
6. Talend Open Studio (TOS)
Talend Open Studio is a popular open-source data integration software that features a user-friendly GUI.
Users can drag and drop components, configure them, and connect them to create data pipelines. Behind the scenes, Open Studio converts the graphical representation into Java and Perl code.
As an open-source tool, TOS is an affordable option with a wide variety of data connectors, including RDBMS and SaaS connectors.
The platform also benefits from an active open-source community that regularly contributes to documentation and provides support.
7. Pentaho Data Integration (PDI)
Pentaho Data Integration (PDI) is an ETL tool offered by Hitachi.
It captures data from various sources, cleans it, and stores it in a uniform and consistent format.
Formerly known as Kettle, PDI features multiple graphical user interfaces for defining data pipelines. Users can design data jobs and transformations using the PDI client, Spoon, and then run them using Kitchen. For example, the PDI client can be used for real-time ETL with Pentaho Reporting.
8. Hadoop
Hadoop is an open-source framework for processing and storing big data in clusters of computer servers.
It is considered the foundation of big data and enables the storage and processing of large amounts of data.
The Hadoop framework consists of several modules, including the Hadoop Distributed File System (HDFS) for storing data, MapReduce for reading and transforming data, and YARN for resource management.
Hive is commonly used to convert SQL queries into MapReduce operations.
Companies considering Hadoop should be aware of its costs.
A significant portion of the cost of implementing Hadoop comes from the computing power required for processing and the expertise needed to maintain Hadoop ETL, rather than the tools or storage themselves.
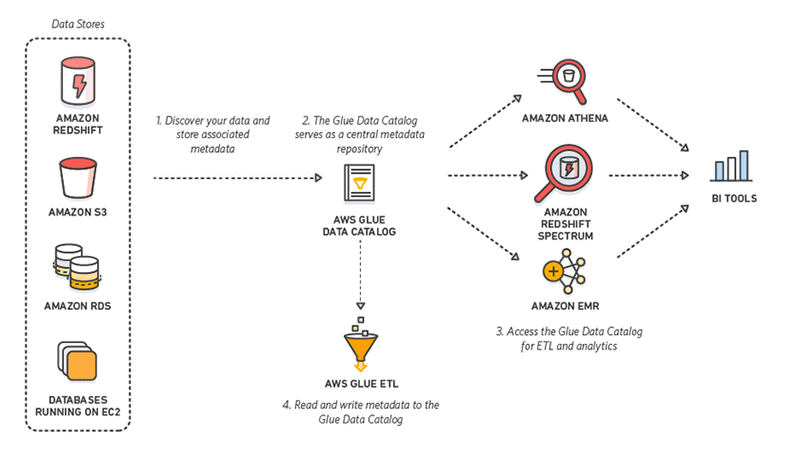
9. AWS Glue
AWS Glue is a serverless ETL tool offered by Amazon.
It discovers, prepares, integrates, and transforms data from multiple sources for analytics use cases.
With no requirement to set up or manage infrastructure, AWS Glue promises to reduce the hefty cost of data integration.
Better yet, when interacting with AWS Glue, practitioners can choose between a drag-and-down GUI, a Jupyter notebook, or Python/Scala code.
AWS Glue also offers support for various data processing and workloads that meet different business needs, including ETL, ELT, batch, and streaming.
10. AWS Data Pipeline
AWS’s Data Pipeline is a managed ETL service that enables the movement of data across AWS services or on-premise resources.
Users can specify the data to be moved, transformation jobs or queries, and a schedule for performing the transformations.
Data Pipeline is known for its reliability, flexibility, and scalability, as well as its fault-tolerance and configurability.
The platform also features a drag-and-drop console for ease of use. Additionally, it is relatively inexpensive.
A common use case for AWS Data Pipeline is replicating data from Relational Database Service (RDS) and loading it onto Amazon Redshift.
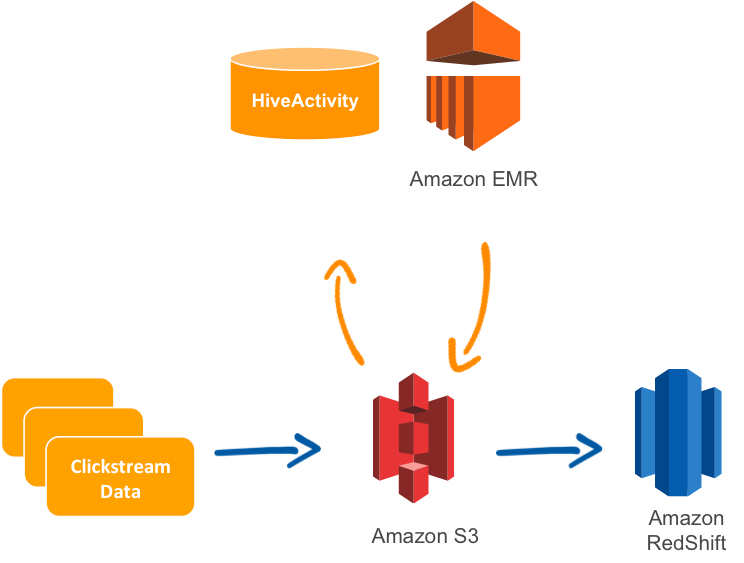
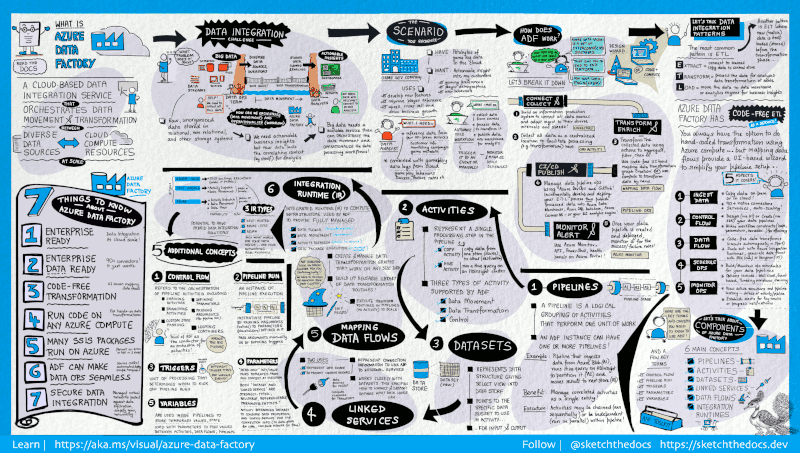
11. Azure Data Factory
Azure Data Factory is a cloud-based ETL service offered by Microsoft used to create workflows that move and transform data at scale.
It comprises a series of interconnected systems.
Together, these systems allow engineers to not only ingest and transform data but also design, schedule, and monitor data pipelines.
The strength of Data Factory lies in the sheer number of its available connectors, from MySQL to AWS, MongoDB, Salesforce, and SAP.
It is also lauded for its flexibility; users can choose to interact with either a no-code graphical user interface or a command-line interface.
12. Google Cloud Dataflow
Dataflow is the serverless ETL service offered by Google Cloud.
It allows for both stream and batch data processing and does not require companies to own a server or cluster.
Instead, users only pay for the resources consumed, which scale automatically based on requirements and workload.
Google Dataflow executes Apache Beam pipelines within the Google Cloud Platform ecosystem.
Apache offers Java, Python, and Go SDKs for representing and transferring data sets, both batch and streaming.
This allows users to choose the appropriate SDK for defining their data pipelines.
13. Stitch
Stitch describes itself as a simple, extensible ETL tool built for data teams.
Stitch’s replication process extracts data from various data sources, transforms it into a useful raw format, and loads it into the destination.
Its data connectors included databases and SaaS applications. Destinations can include data lakes, data warehouses, and storage platforms.
Given its simplicity, Stitch only supports simple transformations and not user-defined transformations.
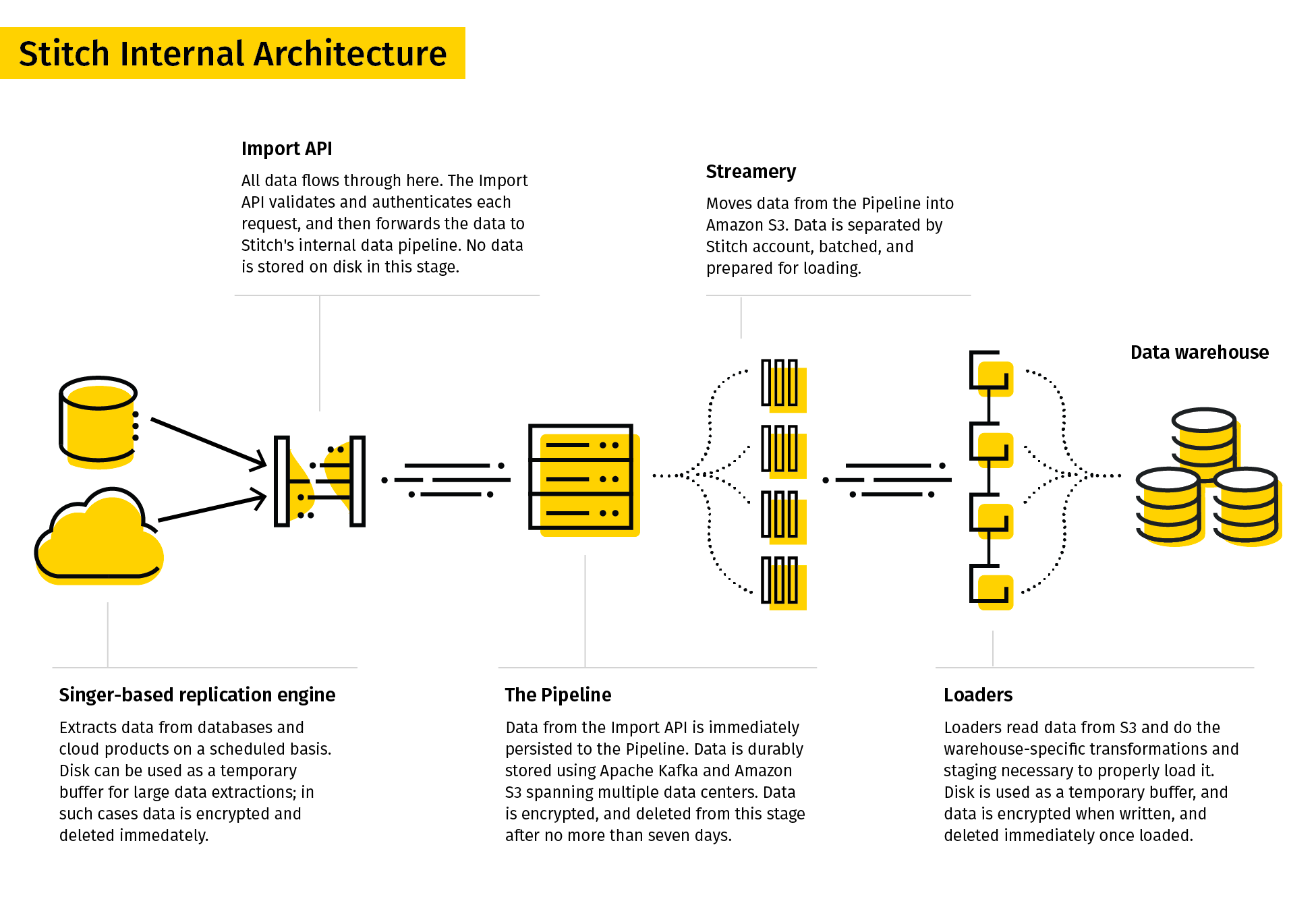
14. SAP BusinessObjects Data Services
SAP BusinessObjects Data Services is an enterprise ETL tool that allows users to extract data from multiple systems, transform it, and load it into data warehouses.
The Data Services Designer provides a graphical user interface for defining data pipelines and specifying data transformations.
Rules and metadata are stored in a repository, and a job server runs the job in batch or real time.
However, SAP data services can be expensive, as the cost of the tool, server, hardware, and engineering team can quickly add up.
SAP Data Services is a good fit for companies that use SAP as their Enterprise Resource Planning (ERP) system, as it integrates seamlessly with SAP Data Services
15. Hevo
Hevo is a data integration platform for ETL and ELT that comes with over 150 connectors for extracting data from multiple sources.
It is a low-code tool, making it easy for users to design data pipelines without needing extensive coding experience.
Hevo offers a range of features and benefits, including real-time data integration, automatic schema detection, and the ability to handle large volumes of data.
The platform also comes with a user-friendly interface and 24/7 customer support.
16. Qlik Compose
Qlik Compose is a data warehousing solution that automatically designs data warehouses and generates ETL code.
This tool automates tedious and error-prone ETL development and maintenance. This shortens the lead time of data warehousing projects.
To do so, Qlik Compose runs the auto-generated code, which loads data from sources and moves them to their data warehouses.
Such workflows can be designed and scheduled using the Workflow Designer and Scheduler.
Qlik Compose also comes with the ability to validate the data and ensure data quality. Practitioners who need data in real-time can also integrate Compose with Qlik Replicate.
17. Integrate.io
Integrate.io, formerly known as Xplenty, earns a well-deserved spot on our list of top ETL tools.
Its user-friendly, intuitive interface opens the door to comprehensive data management, even for team members with less technical know-how.
As a cloud-based platform, Integrate.io removes the need for any bulky hardware or software installations and provides a highly scalable solution that evolves with your business needs.
Its ability to connect with a wide variety of data sources, from databases to CRM systems, makes it a versatile choice for diverse data integration requirements.
Prioritizing data security, it offers features like field-level encryption and is compliant with key standards like GDPR and HIPAA.
With powerful data transformation capabilities, users can easily clean, format, and enrich their data as part of the ETL process.
No posts found!





